One of the most common issues in software development is internationalization/localization. Many smaller developers neglect these tasks entirely when starting out, and adding proper support later turns out to be a major headache. Adding proper support from the start isn’t terribly difficult. FreePascal/Lazarus includes native support for localization of user interface elements for GUI applications, and translatable strings source code. Database specific localization support, however is not handled by FreePascal, nor is it included with most database tools.
I will describe a simple and scalable strategy for database internationalization support, so please feel free to use it in your applications.
The first approach most people try is simply using VARCHAR fields in the database wherever they need strings.
You want a description or whatever for a particular item in a table, so you add some type of text field and end up with something like the following:
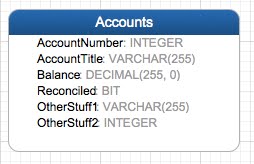
In our fictional Accounting program we have a table called “Accounts”, which contains an Account Number, and an Account Title.
The only problem is: The Title to Number relationship is 1:1. What do we do when we want to support multiple languages?
Solutions:
1. We could keep things as-is and add another table to support our internationalization efforts.
2. We could re-design things to be language neutral.
Of course option 2 is better, because in the example above, the language used in the text field is not even defined. Even if you defined the default field to be say, English, the user of the program may not even use that language. Defining the field to be “The local language” means that any database shared by multiple users will not be consistant.
How to re-design the table, then?
We replace the text field with a text key, and make a new table that contains the text key and also the text:
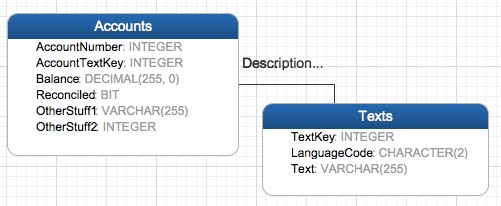
Now whenever anyone inserts an entry into the Accounts table, you will first take the test and insert it into the language table, along with a LanguageCode to specify the language of the string. After that, you can insert the Accounts row, and point it to the appropriate text entry using TextKey. (Obviously, you may want to have another table with a list of valid language codes and link that to the LanguageCode of the Texts table).
You may take the language code to use from the operating system, or store the user’s language preference as a paramater in a user table, depending upon the application.
When all is said and done, you may end up with something resembling the following:
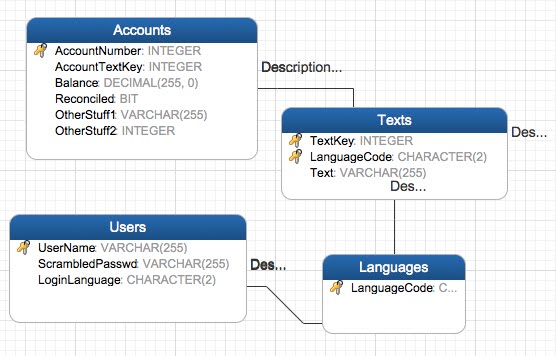
The only problem is that since the text is now stored in a text table instead of the main table, when you query the main table, you just get a bunch of numbers. This can of course be solved by joining the text table in during queries, and even made to look like the old table by using a view. The main problem is that when the user’s language is say, Korean, but only English is stored in the database for a certain entry, you are either going to miss the entry entirely, or get blank text – depending on the type of join.
Additional Considerations
In reality, you usually want a fallback language. For example, if German text doesn’t exist, return the English text instead. This is a pain to implement efficiently in straight SQL, but easy enough in application logic (Including PL/SQL, etc.). When inserting new text items you will need to get the latest unused number, so an auto-number field might be a good idea. On the other hand, using a GUID as the identifier would alleviate you from that trouble and allow easier merging of separate databases later. Using a hash of the input works very well if you want to determine the text based on the key of another table.
Having one large text table with a single namespace as shown in the schema above may or may not be for you. Other common schemes are:
1. Create another key field in the text table which contains the name of the table the text is being stored for
2. Create a separate text table for every base table.
Option 2 is better for very large systems due to table locking concerns and the ability to check entire tables easily – however it makes code more complicated, and may lower performance on smaller systems.

{kind=link}